SupeSite 7.0 �ɼ�����-�����C�����f���̳�_SupeSite�̳�
���ν��| SupeSite �IJɼ��������ܕ����X�y�����֣����Č�������Ϥ SupeSite �IJɼ������������Լ�����r�����Լ��IJɼ�����
�Բɼ� http://vip.book.sina.com.cn/book/index_40931.html ������
һ�����Ⱥ����fһ�������ɼ����Ļ���ԭ����˼·
1���_���ɼ���浽 “�б����朽�” ��
2���_�����@Щ���Ҫ�ɼ��ă��݅^��Ҳ���� “�б�^���R�eҎ�t” ��
3���_��Ҫ�ɼ�������朽ӣ�Ҳ���� “����朽� url �R�eҎ�t” ��
4���F����������Ҫ�ɼ��ķ��������� “�����}�R�eҎ�t” �� “�������R�eҎ�t” ��
5������ 4 �����E�ѽ��_���˲ɼ��ķ������������Ҫ�^�V���}�̓��ݣ�Ո��������Ҫ���O�� “�^�VҎ�t” ��
���ώׂ����E�_����������ͨ�^�鿴���Դ�a���M���O�õģ���ȡ�ķ�����ҪһЩ�����h���c��߅�� “�yԇ” �����Ƿ�ɹ���
����������B�ɼ����Ļ���ԭ���Ͳ��E
1���M����_ => �ɼ����� => �����C���ˣ����D��ʾ��
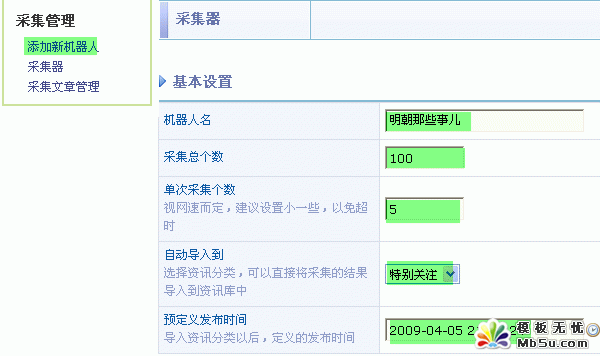
1��������O��
“�δβɼ�����”�M���O���^С�Ĕ��֣����ⳬ�r��
2���ɼ����� url ��ַ�O��
�ɼ����� url ��ַ�ЃɷN�O�÷������ք�ݔ����Ԅ����L���ք�ݔ����Ҫ���Լ�������ɼ��ĵ�ַ����ݔ�롣�Ԅ����Lֻ������ɼ����ĵ�ַ�����퓴a���� [page] ������׃�������ք�ݔ����������D��ʾ��
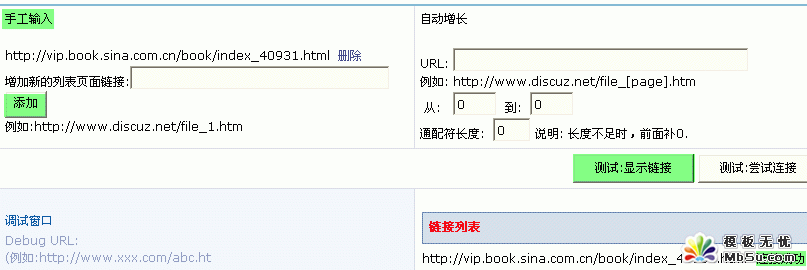
3���ɼ���澎�a
����ɼ������;Wվ�IJ�һ�ӣ���Ҫ��¾��a����ֻ��Ҫ�c���������o���R�e�������R�e����������Dλ�á����D��ʾ��

4���б�^���R�eҎ�t
����Ҫ�ɼ���������c��������I => �鿴Դ���a => �ҵ�����朽�URL�^��
����朽� URL �^�� �� [list] ��ʾ
��߅ div ���������˺�һ��Ҫ�x�ã��@��һ��Ҫע�⣬����朽� URL �^��һ��Ҫ���@�� div �ȣ�����������ģ���һ�o���ġ�
���h����� Dreamweaver ���߲鿴
��߅�ǽ�����߅�� div �Y����Ę˺������磺
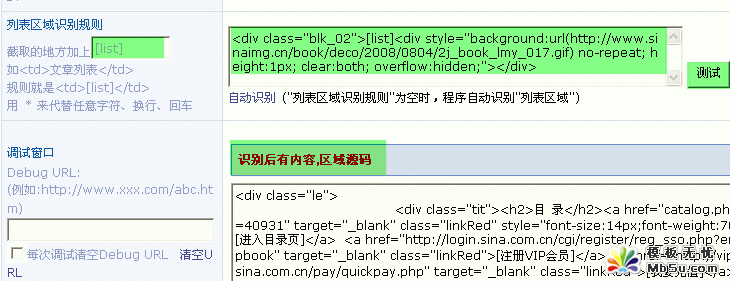
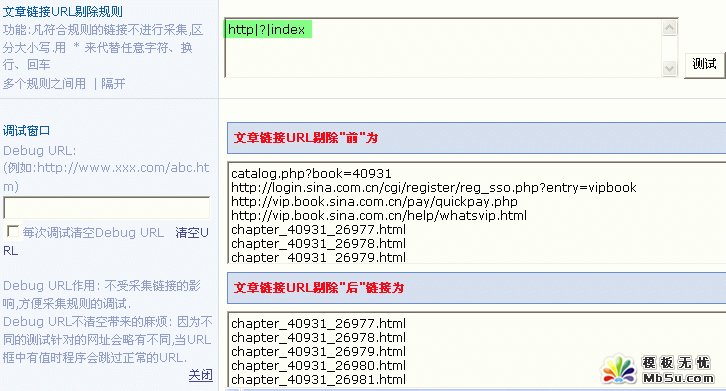
5������朽� URL �R�eҎ�t
�F����Ҫ���B�ӣ����D��ʾ��

朽ӵ�ַ�� [url] ��ʾ�����磺
��������朽� URL Ҏ�t�l�F��Щ朽��Dz���Ҫ�ģ�������Ҫʹ��“����朽�URL��Ҏ�t”�����D��ʾ��
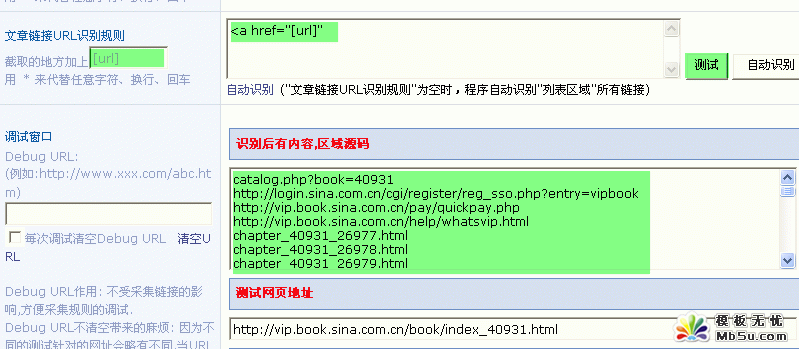
6������朽� URL ��Ҏ�t
��Ҏ�t����ж����x��Ո�� | ���_�����磺
���D��ʾ��
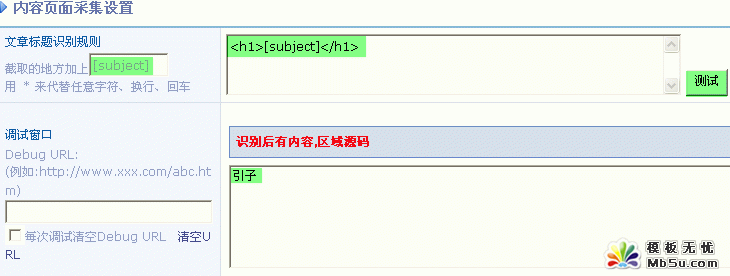
7�������}�R�eҎ�t
�cһ������朽� => ���´��_��������c��������I => �鿴Դ���a => �ҵ��@ƪ���µĘ��}��������Ę˺�
���}�� [subject] ��ʾ�����磺
���D��ʾ��
8���������R�eҎ�t
�cһ������朽� => ���´��_��������c��������I => �鿴Դ���a => �ҵ��@ƪ���µă�����������Ę˺�
������ [message] ��ʾ�����磺
���D��ʾ��

2���@�Ӳɼ�Ҏ�t�͌����ˣ��c���ύ���档������D���c���_ʼ�ɼ������D��ʾ��

3���ɼ����^�̣����D��ʾ��

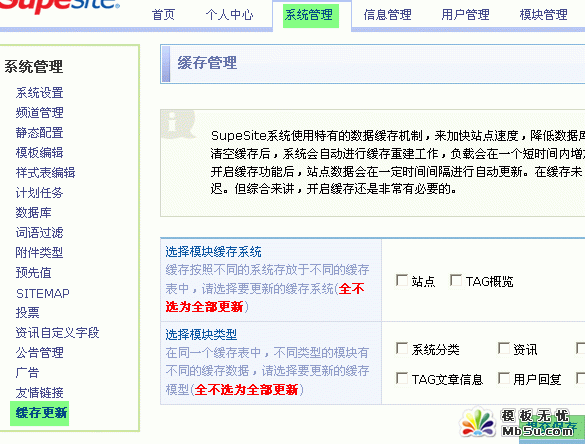
4���ɼ��ꮅ֮��߀��Ҫ�����¾��棬���D��ʾ��
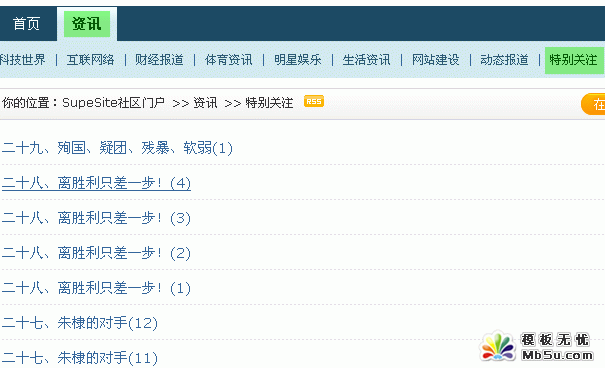
5��������IJɼ�Ҏ�t���_�����_��퓾Ϳ��Կ�������ɼ����ă��ݣ����D��ʾ��
�鿴���� supesite�̳� supesiteģ��
- SupeSiteĬ�J���c݆�D�D������������
- SupeSite7.5 �YӍ�l�����ڸ��ӂ��Ի�
- SupeSite7.5 ���T���ē��в�ͬ��title����ʾ��Ϣ
- SupeSite7.5 benbaHTML���ɷ�����һ��
- SupeSite7.5�l���uՓ��ֱ�����D�ص�����������������
- SupSite7.5������l������o���L��
- SupSite7.5��ꑺ��_����C���ކ��}��Q����
- SupSiteģ�͟o�����uՓ�ķ���
- SupSiteģ���{���õ����ׂ��˺����f��
- SupSite����ļ��cģ�K�Pϵ�f��
- ����SupeSite7.5���FErrno.: 1054�Ľ�Q����
- SupeSite7.5 ��gbk�汾�����ڻ؏�ij���ӕr�؏ͱ��ؔ��ķ���
SupeSite�̳̳̽�Rssӆ�Cms�̳�����
SupeSite�̳����]
- SupeSite 7.0 ˮӡ�O�ý̳�
- SupeSite7.5�l���uՓ��ֱ�����D�ص�����������������
- SupeSite 7.0 ϵ�y����-ͶƱ�̳�
- SupeSite 7.0 ���_ �� �������Ľ̳�
- SupSite7.5��ꑺ��_����C���ކ��}��Q����
- SupeSite 7.0 ģ����-ģ�����̳�
- SupeSite 7.0 ����ģ�K/ģ�K�����f���̳�
- SupeSite7.5 benbaHTML���ɷ�����һ��
- SupeSite 7.0 ��Ϣ����-�YӍ�ȼ����˽̳�
- SupeSite 7.0 �����S�o-�uՓ�����f���̳�
����Ҳϲ�g���@Щ
- ���P朽ӣ�
- �̳��f����
SupeSite�̳�-SupeSite 7.0 �ɼ�����-�����C�����f���̳�
 ��
��