hash��solr�ں�����(sh��)��(j��)�ֲ�ʽ���������еđ�(y��ng)�ý̳�_MySQL�̳�
���]��23����ȫ�T���TMySQL��(sh��)��(j��)��ʹ��MySQL����ȫ���}���ܲ�ע�⡣������MySQL��ʾ��23��ע����헣� 1.����͑��˺ͷ���(w��)���˵��B����Ҫ��Խ��ͨ�^�������εľW(w��ng)�j(lu��)����ô����Ҫʹ��SSH����������ԓ�B�ӵ�ͨ�š� 2.��set password�Z������Ñ����ܴa���������E����mysql -u root��ꑔ�(sh��)��(j��)��ϵ�y(t��ng)��Ȼ��mys
����Solr��һ����������I(y��)��������(y��ng)�÷���(w��)�����������ṩ�����Web-service��API�ӿڡ��Ñ�����ͨ�^httpՈ���������������(w��)���ύһ����ʽ��XML�ļ�����������.
������(li��n)�W(w��ng)��(chu��ng)�I(y��)�д��˶��Dzݸ���(chu��ng)�I(y��)���@���r��]�Џ��ŵķ���(w��)����Ҳ�]���Xȥ�I�ܰ��F�ĺ�����(sh��)��(j��)�졣���@�Ӈ����ėl���£�һ����һ���Ą�(chu��ng)�I(y��)�ߏĄ�(chu��ng)�I(y��)�Ы@�óɹ����@���ͮ�ǰ���_Դ���g(sh��)��������(sh��)��(j��)�ܘ�(g��u)�����ز��ɷֵ��P(gu��n)ϵ�������҂�ʹ��mysql��nginx���_Դܛ����ͨ�^�ܘ�(g��u)�͵ͳɱ�����(w��)��Ҳ���Դǧ�f���Ñ��L������ϵ�y(t��ng)�����������Ԍ��W(w��ng)���vӍ�ȴ��ͻ�(li��n)�W(w��ng)��˾��ʹ���˺ܶ��_Դ���Mϵ�y(t��ng)���������ƽ�_�����ԣ���ʲô�]�P(gu��n)ϵ��ֻҪ�܉��ں�������r�²��ú����Ľ�Q������
��������ô�һ���õ�ϵ�y(t��ng)�ܘ�(g��u)��?�@��Ԓ�}̫���@����Ҫ�fһ��(sh��)��(j��)�����ķ�ʽ�������҂��Ĕ�(sh��)��(j��)�����(w��)��ֻ�ܴ惦200����(sh��)��(j��)��ͻȻҪ��һ������A(y��)���_��600����(sh��)��(j��)��
�������Բ��ÃɷN��ʽ���M��Uչ���߿v��Uչ��
�����v��Uչ����������(w��)����Ӳ���YԴ�������S���C������������Խ�ߣ��r��Խ�ߣ��@�����r����һ���С��˾�dzГ�(d��n)����ġ�
�����M��Uչ�Dz��ö������r�ęC���ṩ����(w��)���@��һ���C��ֻ��̎��200����(sh��)��(j��)��3���C���Ϳ���̎��600����(sh��)��(j��)�ˣ�����Ժ�I(y��)��(w��)������߀���Կ����������ӡ��ڴ����(sh��)��r���x��M��Uչ�ķ�ʽ�����D��

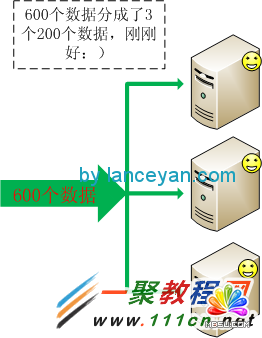
�����F(xi��n)���Ђ����}�ˣ��@600����(sh��)��(j��)���·�ɵ�����(y��ng)�ęC������Ҫ���]���������䣬���O(sh��)�҂�600����(sh��)��(j��)���ǽy(t��ng)һ������id��(sh��)��(j��)����1~600���ֳ�3 �ѿ��Բ��� id mod 3�ķ�ʽ���䌍���挍�h(hu��n)�����ܲ����@�Nid���ַ�������Ҫ���ַ����D(zhu��n)׃?y��u)�hashcode���M��ȡģ��
����Ŀǰ�������Dz��ǽ�Q�҂��Ć��}�ˣ����Д�(sh��)��(j��)���ܺõķְl(f��)���қ]���_��ϵ�y(t��ng)��ؓ�d��������҂��Ĕ�(sh��)��(j��)��Ҫ�惦����Ҫ�xȡ�͛]���@ô�����ˡ��I(y��)��(w��)������ô�k����Ұ�������ęM��Uչ֪����Ҫ����һ�_����(w��)�������Ǿ�����������@һ�_����(w��)��������һЩ���}���������@�����ӣ�һ��9����(sh��)����Ҫ�ŵ�2�_�C��(1��2)�ϡ������C����Ş飺1̖�C�����1��3��5��7��9 ��2̖�C����� 2��4��6��8������Uչһ�_�C��3��Σ���(sh��)��(j��)��Ҫ�l(f��)�����w�ƣ�1̖�C�����1��4��7, 2̖�C�����2��5��8, 3̖�C�����3��6��9����D��

�����ĈD�п��Կ��� 1̖�C����3��5��9�w�Ƴ�ȥ�ˡ�2�ÙC����4��6�w�Ƴ�ȥ�ˣ������µ����������·�����һ�顣��(sh��)��(j��)��С��Ԓ���·���һ����r����������҂������σ|����T���Ĕ�(sh��)��(j��)�@�������ɱ����ஔ?sh��)ĸߣ��لt�ׂ�С�r���t��(sh��)�졣�����w�Ƶĕr��ԭ��(sh��)��(j��)��C��ؓ�d���^�ߣ��Ǵ�Ҿ����Ɇ��ˣ��Dz����@�Nˮƽ�Uչ�ļܘ�(g��u)��ʽ��̫����?
����—————————–�A���ָ—————————————
����һ����hash�������@�N��(y��ng)�ñ���������ģ��F(xi��n)�ڱ��V����(y��ng)���ڷֲ�ʽ���棬����memcached�����溆�ν�B��һ����hash�Ļ���ԭ��������İ汾 http://dl.acm.org/citation.cfm?id=258660������(n��i)�W(w��ng)���кܶ����¶����ı��^�á��磺 http://blog.csdn.net/x15594/article/details/6270242
�������溆���e�����Ӂ��f��һ����hash��
�����ʂ䣺1��2��3 ���_�C��
����߀�д������9����(sh��) 1��2��3��4��5��6��7��8��9
����һ����hash�㷨�ܘ�(g��u)
�������E
����һ����(g��u)����� 2��32�η� ��̓�M��(ji��)�c���������Ӌ��C������01�����磬�M�Є��֕r����2�Ĵη���(sh��)��(j��)��������⡣�� 2��32�η���42�|���҂������г������ķ���(w��)��Ҳ�����ܳ��^42�|�_�ɣ��Uչ�;����Զ����C�ˡ�

�������������_�C���քeȡIP�M��hashcodeӋ��(�@��Ҳ����ȡhostname��ֻҪ�܉�Ψһ�^(q��)�e�����C���Ϳ�����)��Ȼ��ӳ�䵽2��32�η���ȥ������1̖�C���������hashcode����mod (2^32)�� 123(�@����̓��(g��u)��)��2̖�C���������ֵ�� 2300420��3̖�C�������� 90203920���@�����_�C����ӳ�䵽���@��̓�M��42�|�h(hu��n)�νY(ji��)��(g��u)�Ĺ�(ji��)�c���ˡ�

������������(sh��)��(j��)(1-9)Ҳ��ͬ�ӵķ������hashcode����42�|ȡģ�������õ��h(hu��n)�ι�(ji��)�c�ϡ����O(sh��)�@�ׂ���(ji��)�c�������ֵ�� 1��10��2��23564��3��57��4��6984��5��5689632��6��86546845��7��122��8��3300689��9��135468�����Կ��� 1��3��7С��123�� 2��4��9 С�� 2300420 ���� 123�� 5��6��8 ���� 2300420 С��90203920���Ĕ�(sh��)��(j��)ӳ�䵽��λ���_ʼ형rᘲ��ң�����(sh��)��(j��)���浽�ҵ��ĵ�һ��Cache��(ji��)�c�ϡ�������^2^32��Ȼ�Ҳ���Cache��(ji��)�c���͕����浽��һ��Cache��(ji��)�c�ϡ�Ҳ����1��3��7�����䵽1̖�C����2��4��9�����䵽2̖�C����5��6��8�����䵽3̖�C����

�����@���r���ҿ��ܕ������ҵ��F(xi��n)�ڛ]�п�Ҋһ����hash�����κκ�̎���Ȃ��y(t��ng)��ȡģ߀�����ˏ�(f��)�s�ȡ��F(xi��n)���R�ρ���һЩ�P(gu��n)�I�Ե�̎���������҂�����һ�_�C��������ԭ���҂���Ҫ�����еĔ�(sh��)��(j��)���·��䵽���_�C����һ����hash��ô����?�F(xi��n)��4̖�C�����M��������hashֵ�����ȡģ����12302012�� 5��8 ����2300420 С��12302012 ��6 ���� 12302012 С��90203920 ���@���{(di��o)����ֻ�ǰ�5��8��3̖�C���h����4̖�C���м��� 5��8��

����ͬ�����h���C����ô���أ����O(sh��)2̖�C���������Ӱ푵�Ҳֻ��2̖�C���ϵĔ�(sh��)��(j��)���w�Ƶ��x����(ji��)�c���ψD��4̖�C����

������MySQL 5.0 ��(sh��)��(j��)�������ԵĴ惦�^�������ύһ����ԃ�ĕr��MySQL�������������Ƿ������һЩ��(y��u)��ʹ̎��ԓ��ԃ���ٶȸ��졣�@һ������B��ԃ��(y��u)��������ι����ġ��������֪��MySQL���õă�(y��u)���ֶΣ����Բ鿴MySQL�����փԡ� ��Ȼ��MySQL��ԃ��(y��u)����Ҳ������������������Ҳʹ��������һЩ��Ϣ�����磬��
- 23����ȫ�T���TMySQL��(sh��)��(j��)��
- MySQL 5.0 ��(sh��)��(j��)�������ԵĴ惦�^��
- MySql������һ�c�ĵ�
- mysql��(d��o)�딵(sh��)��(j��)���ļ�������Ƶ��ķ���
- Mysql�惦����InnoDB��Myisam������^(q��)�e
- Mysql�\�Эh(hu��n)����(y��u)��(Linuxϵ�y(t��ng))
- MySQL��ԃ�����܃�(y��u)�����A(ch��)�̳�
- MySQL ��windows�ϵİ��bԔ����B
- sql server 2005�r�l(f��)��18452�e�`��Q����
- MySQL�ֶε�ȡֵ����
- mysql_unbuffered_query�cmysql_query�ą^(q��)�e
- mysql ��(f��)�Ʊ픵(sh��)��(j��)�����Y(ji��)��(g��u)��3�N����
MySQL�̳�Rssӆ����̳̽�����
MySQL�̳����]
- MySQL���������п��Y(ji��)�ռ�
- ��������SQL���ķN�B��-�����B�ӡ������B�ӡ���(n��i)�B�ӡ�ȫ�B��
- mysql�ܴa�^�ڌ�(d��o)���B�Ӳ���mysql
- MySQL�Pӛ֮ҕ�D��ʹ��Ԕ��
- MySQL�ֶε�ȡֵ����
- MySQL�İ�ȫ���}�İ��b�_ʼ�f��
- ����mysql��:�α�distinct�����group by��ԃ?n��i)����؏?f��)ӛ�
- MYSQL�Č�(d��o)�댧(d��o)���c߀ԭ���
- Win7 ϵ�y(t��ng)�ϰ��bSQL Server 2008�D��̳�
- �W(w��ng)վ��(sh��)��(j��)���˷����ԓ��ô�k��
����Ҳϲ�g���@Щ
- ����SQLҕ�D�������SQL Server��(sh��)��(j��)���ֵ�
- ��QSQL Server��(sh��)��(j��)���(qu��n)�ޛ_ͻ����������
- SQL Server��(sh��)��(j��)��������?zh��n)���w�
- ѭ��u�M�v�┵(sh��)��(j��)����ʮ�����O(sh��)Ӌԭ�t
- ՄSQL Data Services���ɞ����������Ĕ�(sh��)��(j��)��
- ��ΰ���Ĕ�(sh��)��(j��)�����ڰ汾����֮��
- char��varchar��text��nchar��nvarchar��ntext�ą^(q��)�e
- mssql2005��(sh��)��(j��)���R���̳�
- ��һ�lsqlȡ�õ�10����20�l��ӛ�
- ���xSQL Server��(sh��)��(j��)���ݵķ���
- ���P(gu��n)朽ӣ�
��(f��)�Ʊ��朽�| ����hash��solr�ں�����(sh��)��(j��)�ֲ�ʽ���������еđ�(y��ng)�ý̳�
- �̳��f����
MySQL�̳�-hash��solr�ں�����(sh��)��(j��)�ֲ�ʽ���������еđ�(y��ng)�ý̳�
 ��
��